
Supposons que l'on ait un fichier XML dont les premières lignes sont les suivantes :
<?xml version="1.0" encoding="ISO-8859-1"?>
<dataroot>
<row>
<Client>Pepsi-Cola</Client>
<Zone>Nord</Zone>
<Vendeur>Anselme</Vendeur>
<Date>05/02/2008</Date>
<CA_x0020_ventes>6000</CA_x0020_ventes>
<Produit>Spray Dépoussiérant Clavier</Produit>
</row>
Le fichier est composé d'un en-tête indiquant la version XML utilisée suivi de plusieurs balises indiquant en résumé que pour chaque ligne (row), il y a des informations concernant les champs Client, Zone, Vendeur, Date, CA Ventes et Produit.
Nous souhaitons récupérer ces informations afin de les insérer dans un flux de donnée via Visual Integrator.
Pour cela nous allons créer un script qui va utiliser un objet d'entrée XML. Cet objet est disponible à partir de la version 5.1.31 de Visual Integrator et de Data Integrator.
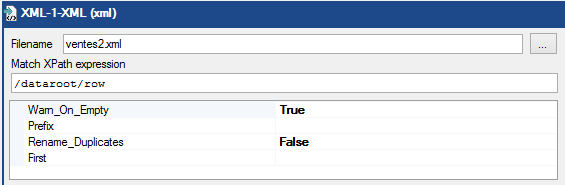
Dans la zone Filename, nous allons renseigner le chemin du fichier XML (dans notre exemple il s'agit de ventes.xml).
Dans la zone Match Xpath Expression, nous allons indiquer la syntaxe permettant d'identifier un ensemble de nœuds dans un document XML. Comme nous souhaitons récupérer tous les champs de chaque ligne, nous allons indiquer la valeur /dataroot/row (sélection des balises row "filles" des balises dataroot) ou bien encore la valeur //row (toutes les balises row) ; le résultat sera le même.
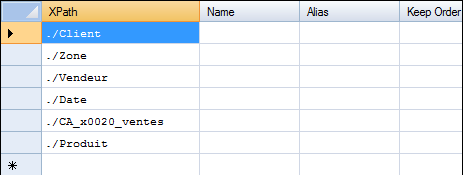
Ensuite il nous faut définir les champs à afficher / récupérer.
Pour cela il faut insérer dans le tableau de la partie de droite les différentes valeurs de champs dans la zone Xpath. La syntaxe sera la suivante <nom_du_champ> ou bien ./<nom_du_champ>.
Voici une capture d'écran des différents paramètres insérés dans notre exemple :
Et l'on obtient le résultat suivant après avoir lancé un test sur l'objet :
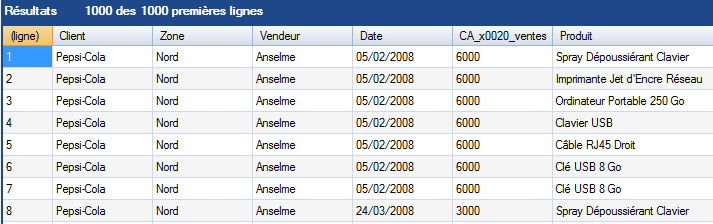
Il y a possibilité de renommer les champs en renseignant la zone Name dans le tableau en cas de nécessité.
